Corpus Annotated Arabic Gospel Manuscripts: A Prototype
Several attempts were made to study the linguistic features of the Arabic translations of the Gospels in order to identify the different textual traditions. The majority of these projects use verbal agreement between texts to define their identities. In some cases, other techniques were used on a reduced scale in analyzing selected texts. The limitations of these attempts lies in the fact that the studies used only a small number of readings selected from only a few manuscripts and that the selection was not formalized or automated.
To fill these gaps, our project offers automated linguistic corpus processing features. All transcribed texts are subject to a morphosyntactic annotation. Lexical, grammatical and inflectional properties (tense, grammatical mood, grammatical voice, aspect, person, number, gender and case) are associated with the annotated text. These linguistic properties allow the system to perform complex searches based on abstract representations of a specific word, sentence, paragraph, syntax and occurrence.
In order to formalize all possible verbal tokens, we defined a taxonomy of inflectional classes for Arabic verbs. This taxonomy allows the system to encode simultaneously in the lexical representation three variations: inflectional, morphophonemic and orthographic.
Methodology
L’annotation morpho-syntaxique d’un texte consiste essentiellement à associer des informations lexicales, grammaticales et flexionnelles aux formes présentes dans un texte. L’objetif de l’annotation est de pouvoir effectuer des recherches complexes sur une représentation abstraite d’un mot et de lister leur contexte d’occurrence. La recherche est composé de critères de recherche. Les critères peuvent porter, par exemple, sur des variations d’une forme canonique sur des motifs syntaxiques (syntactic pattern), sur des traits flexionnels, ou une combinaison complexe de ces critères. Nous avons choisi l’outil Unitex, un processeur de corpus multilingue, afin de traiter les textes de notre prototype. Le processeur de corpus Unitex a été conçu au départ pour le français et l’anglais. Le traitement des autres langues nécessite des choix linguistiques d’annotation, des adaptations et des ajustements du logiciel de ce processeur.
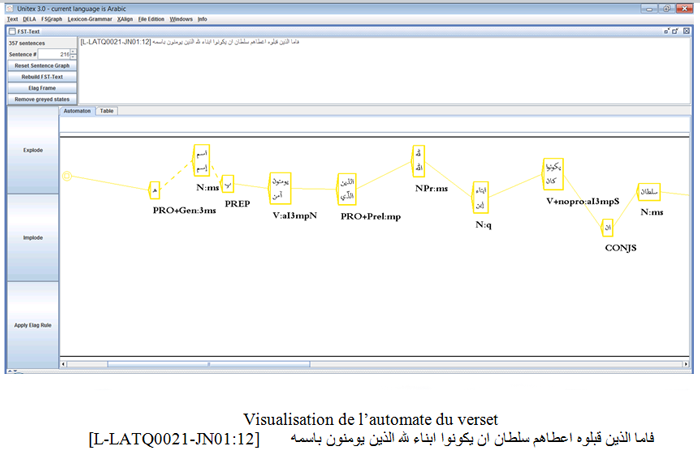
Par rapport au français et l’anglais, la langue arabe se distingue par trois caractéristiques:
- l’ubiquité des infixes, formalisés par des racines et des schèmes dans la morphologie traditionnelle. Ces infixes sont présents dans la conjugaison des verbes, et dans les pluriels brisés;
- l’écriture optionnelle des diacritiques à la fin d’un mot qui marque le cas grammatical dans un texte;
- des agglutinations de particules grammaticales, ou clitiques au debut et en fin de mot.
Afin de donner des solutions pour annoter des formes réalisés en surface, nous avons pris les décisions suivantes.
- Les formes fléchies (verbe conjugué, nom/adjectif au féminin pluriel) seront regroupées sous un même lemme ou forme canonique d’un mot et non sous une racine et un schème. Ainsi, un verbe conjugué sera représenté para un lemme, un ensemble de traits flexionnelles associées à sa conjugaison. Un nom fléchi est représenté par le lemme, généralement au masculin ou féminin singulier, et des traits flexionnels comme genre et nombre et éventuellement définition et cas.
- Quand la diacritique finale est explicitée, le cas de ce nom serait annoté; dans le cas contraire, le cas serait omis de l’annotation. La présence des diacritiques (l’indéfini accusative, /-an/, –aAF, tanwin al-nasb) est non négligeable dans le corpus.
- Une conjonction de coordination, de subordination, une préposition peut s’agglutiner au début d un verbe ou un nom. Un pronom peut s’agglutiner à la fin d un verbe ou un nom. Ces segments sont identifiés dans les formes et seront pris en compte dans l’annotation du corpus.
Un mot est une suite d’un ou plusieurs segments séparées par des accolades { } dont le format est le suivant:
{forme_fléchie,lemme,CAT: traits-flexionnels }
- la forme fléchie est le segment identifié du mot en surface, qui est représenté par un lemme sous-jacent, une catégorie grammaticale et un ensemble de traits flexionnels liés à sa catégorie.
- le lemme sous-jacent est la forme canonique choisi par la tradition grammaticale. Si le lemme est identique à la forme fléchie, alors il est omis.
- CAT est la catégorie grammaticale de ce lemme: Verbe, Nom, Adjectif, Adverbe, préposition, ...
- Les traits-flexionnels sont relatif à la catégorie grammaticale. Pour un verbe: voix, temps, personne, genre, nombre, et mode. Pour un nom: genre, nombre, définition et cas, ...
Les deux exemples suivants illustrent deux suites d’agglutination de segments :
| Autour d’un nom: |
وبافعالهم |
{وَ,.CONJC} {بِ,.PREP} {افعال,فعل.N:q} {هم,ه.PRO+Gen:3mp} |
|
Autour d’un verbe: |
فاعطاهم |
{فَ,.CONJC} {اعطا,أعطى.V+pro:aP3ms} {هم,ه.PRO+Acc:3mp} |
Nous détaillons ci-après les valeurs des traits flexionnels des principales catégories grammaticales, à savoir, les verbes, les noms et les adjectifs.
Pour un verbe, les traits flexionnels sont :
- Voix: active (a), passive (b);
-
Temps:
- Perfect (accompli), Imperfect(inaccompli), Imperatif (Y),
- participe present (F), participe passé (M) ;
- Personne: 1, 2, 3;
- Genre: masculin, feminin;
- Nombre: singulier, duel, pluriel;
- Mode: iNdicatif (N), Subjonctif, Jussif, Energetique.
Pour un nom ou un adjectif, les traits flexionnels sont :
- Genre: masculin, féminin;
- Nombre: singulier, duel, pluriel régulier (p), pluriel brisé(q);
- Définition: Défini, indéfini, annexé (mudaf)
- Cas : Nominatif, Accusatif, Génitif.
Grammatical variations
A language changes over time and varies according to place and social setting. In the case of Arabic, we can observe grammatical variation like differences in the structure of words, phrases or sentences by comparing the same translated Gospel text taken from different manuscripts. One of the most common differences between these manuscripts is the way in which tenses are formed. Our corpus processor provides an appropriate tool capable of formalizing all the instances of the same lemma and drawing the variation graph of its tenses on a timeline. This type of analysis assists the researcher in building a complex system in order to classify the textual traditions. For example, if a Greek verb requires an accusative for its object, the corpus processor can identify the case of all the objects in the Arabic translation of the same verb wherever it is found in the transcribed manuscripts. The results can be grouped and sorted by case. This process can be done in both horizontal (in the same manuscripts) and vertical (in all the manuscripts) ways.
Orthographic variations
Orthographic variations may serve to reveal the identity of the scribe and may also contribute to locate a text on a timeline. The use of diacritics in Arabic Gospel manuscripts remains unstudied. The formalization and abstraction of this use may help the scholar to define sets of standards that enable the text’s grouping according to orthographic variations.
Semantic variations
Many aspects of lexico-semantic variation are linked to a sociolinguistic framework. This interplay between society, culture, religion and language is very strong in Arabic manuscripts of the Gospels. In this perspective the corpus allows the scholars to define semantic arrays through a process of abstraction.
Syntactic variations
The syntax reflects the principles and processes by which sentences are constructed in particular languages. In the case of Arabic Gospels, the syntax underlying the text is one of the strongest characteristics of the linguistic origin of the manuscript. Since it is a sacred text, the translators did their best to make their Arabic translation very close to the original (Greek, Syriac, Latin and potentially other oriental languages). As a result of this effort, they compromised the Arabic syntax and imported the original one, but now using Arabic words. The annotated corpus allows the scholar to define a specific syntax as a pattern and to find all the Arabic instances in the transcribed manuscripts that follow it. For each verse, the researcher can extract its syntax and compare it to that of the same verse in other languages (this requires that the same verse in other languages is annotated in the corpus). This tool may help in identifying formally the Vorlagen of the translations.
Variation in Dialect
It is common in Arabic manuscripts of the Gospels to have different forms for the same inflected word. For example, the same lemma or canonical form of a word may have different forms of broken plural. The current type of analysis allows the scholar to perform a search based on the dialectic pattern of a broken plural identified in a specific text. In this case, the search operation will return all the lemmas or lemmata affected by this pattern. A more advanced search may return the geographical or historical distribution of the lemmas affected by a specific inflectional pattern.
The Prototype
|
Chapitre |
Nombre de manuscrits |
Nombre de versets |
Nombre total de versets |
Nombre de mots |
|
JN01 |
21 |
17 |
357 |
3850 |
|
JN06 |
39 |
6 |
234 |
3400 |
|
JN18 |
35 |
9 |
315 |
4850 |
|
LK08 |
45 |
7 |
315 |
5350 |
|
LK15 |
45 |
22 |
990 |
11528 |
|
MK13 |
37 |
13 |
481 |
5820 |
|
MT07 |
38 |
7 |
266 |
2920 |
|
MT16 |
36 |
4 |
144 |
2257 |
|
Totaux |
|
85 |
3102 |
39975 |